
新闻中心

科研进展
Nature Communications | 鲲鹏院王培培课题组联合密西根州立大学整合多组学数据预测植物复杂性状
全基因组预测(或全基因组选择)在缩短动植物育种周期、提高育种效率等方面起到越来越重要的作用。在以往的研究中,通常只有基因组序列信息被用于全基因组预测中,但植物复杂性状的形成受到多个维度的遗传信息调控,包括基因组序列、基因转录调控、基因甲基化修饰、染色体三维结构与修饰等等。2016年拟南芥1001基因组计划(the Arabidopsis 1001 Genome Project)产生了几百、上千个拟南芥生态型的基因组、转录组、甲基化修饰组,以及多个表型组数据,这使得科研团队得以对多维组学数据在预测植物复杂性状中的应用进行评估。

近日,佛山鲲鹏现代农业研究院联合美国密西根州立大学,在《自然·通讯(Nature Communications)》上在线发表了题为“Prediction of plant complex traits via integration of multi-omics data”的研究论文,整合了基因组、转录组和甲基化修饰组数据对拟南芥多个复杂性状进行预测,揭示了多组学数据相对于单组学数据在预测准确性和鉴定复杂性状关键基因等方面的优势。
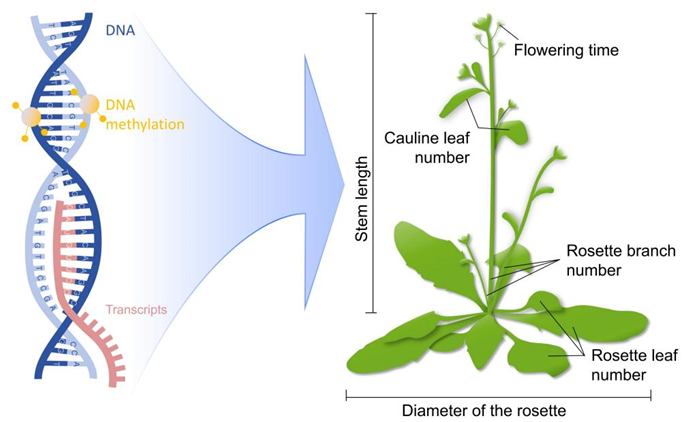
图为拟南芥1001基因组计划产生的多组学和表型组数据示意图。
研究人员发现,尽管不同生态型之间的遗传相似性(基于基因组、转录组或甲基化修饰组,图1)不能很好地反映生态型之间的表型相似性(图2a),但基于3类组学数据的全基因组预测模型却能相对较好地预测与开花时间相关的3个复杂性状(图2b):开花时间、基座叶数目、茎生叶数目。其中,基于转录组和甲基化组数据的预测模型具有与基于基因组数据的模型相当的预测能力;相比于基因体甲基化水平,基于单碱基甲基化水平数据的模型可能具有更好的预测能力。
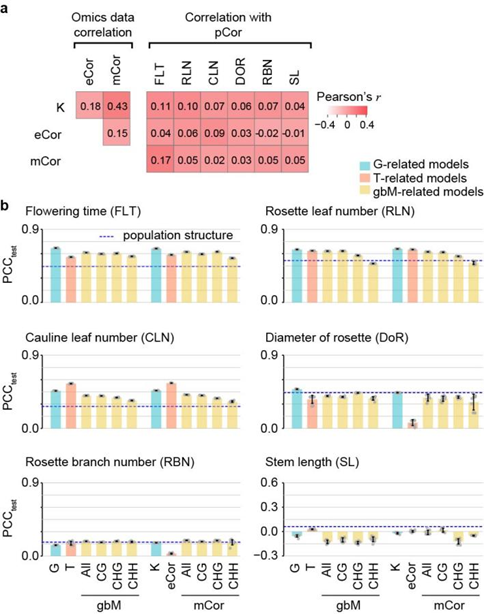
图为不同组学数据在预测植物复杂性状中的表现。
分析对模型预测具有重要贡献的特征,可以鉴定出潜在的复杂性状关键基因。研究人员发现,对已知开花时间调控基因的鉴定会受到多种因素的影响,包括:用于建模的组学数据类型、数据形式、特征重要性衡量方法、植物复杂性状采集时的环境条件、用于建模的生态型数据、在前人研究中鉴定开花时间调控基因时开花时间的衡量方式(比如开第一朵花所用天数、开花前的基生叶数目),等等。此外,研究人员对预测模型推测出的重要基因(但之前未被报道过参与开花时间的调控)进行功能验证,鉴定出了9个新的参与开花时间调控的基因。
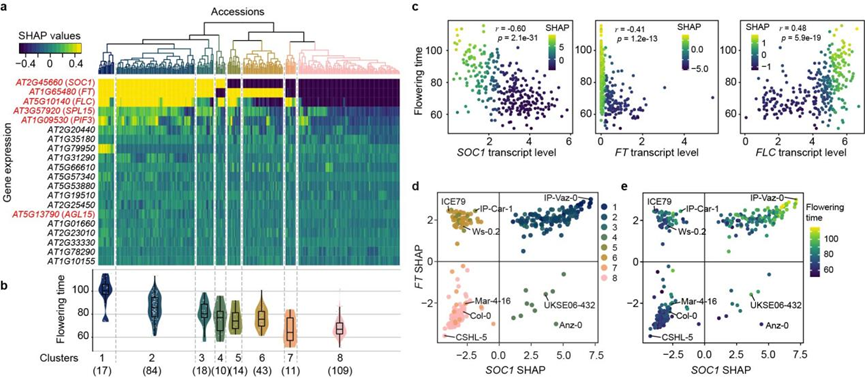
图为生态型特异的特征重要性。
研究人员还发现基因特征对开花时间预测的贡献或重要性是依赖于生态型的。此外,开花时间调控网络中的几个节点基因(比如SOC1,FT和FLC)在表达水平和特征重要性上总体表现出耦合的现象,但在个别生态型中却表现出非耦合的现象(图3)。这些结果说明,人们在实验室常用拟南芥生态型(如Col-0)中所获得的关于开花时间调控机制的一些结论,可能并不适用于所有的生态型。
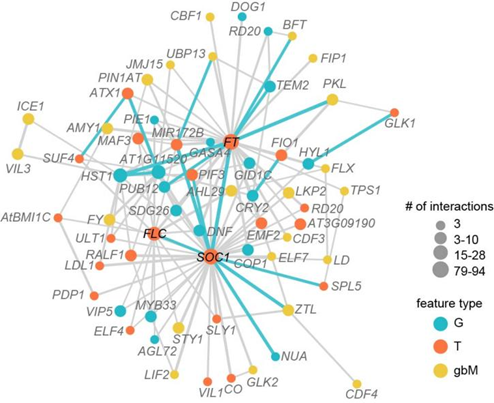
图为基于整合模型的特征互作网络。
对三种组学数据进行整合可以提高模型对开花时间预测的准确性,对整合模型进行解析,还可以获得特征之间的互作网络。研究人员使用426个已知开花时间调控基因的三类特征数据构建了一个整合模型,发现特征之间的互作网络可以较好地复现开花时间调控网络:开花时间调控网络中的几个节点基因(比如SOC1,FT和FLC)也是特征互作网络中的节点基因,具有最多的特征互作关系(图4)。此外,特征互作网络还可以揭示更多潜在的基因互作关系,包括基因之间在不同遗传维度中的调控关系(比如甲基化修饰:表达水平、SNP:甲基化修饰等)。
该研究为利用多组学数据预测植物复杂性状提供理论依据,助力植物育种进入“育种4.0”时代。王培培研究员2023年入选国家级青年人才(生物育种领域),其课题组将充分利用现有高新育种技术,与国内外继续开展合作促进植物育种,助力佛山花卉等产业转型升级。
鲲鹏院王培培研究员为论文第一作者兼共同通讯作者,密西根州立大学Shin-Han Shiu教授为第一通讯作者。密西根州立大学的Melissa D. Lehti-Shiu、Serena Lotreck、Kenia Segura Abá和威斯康辛大学的Patrick J. Krysan参与了此工作。该研究得到了美国能源部大湖生物能源研究中心项目,美国国家科学基金会项目,以及鲲鹏院启动经费、重大科研任务和国家自然科学基金等项目的支持。